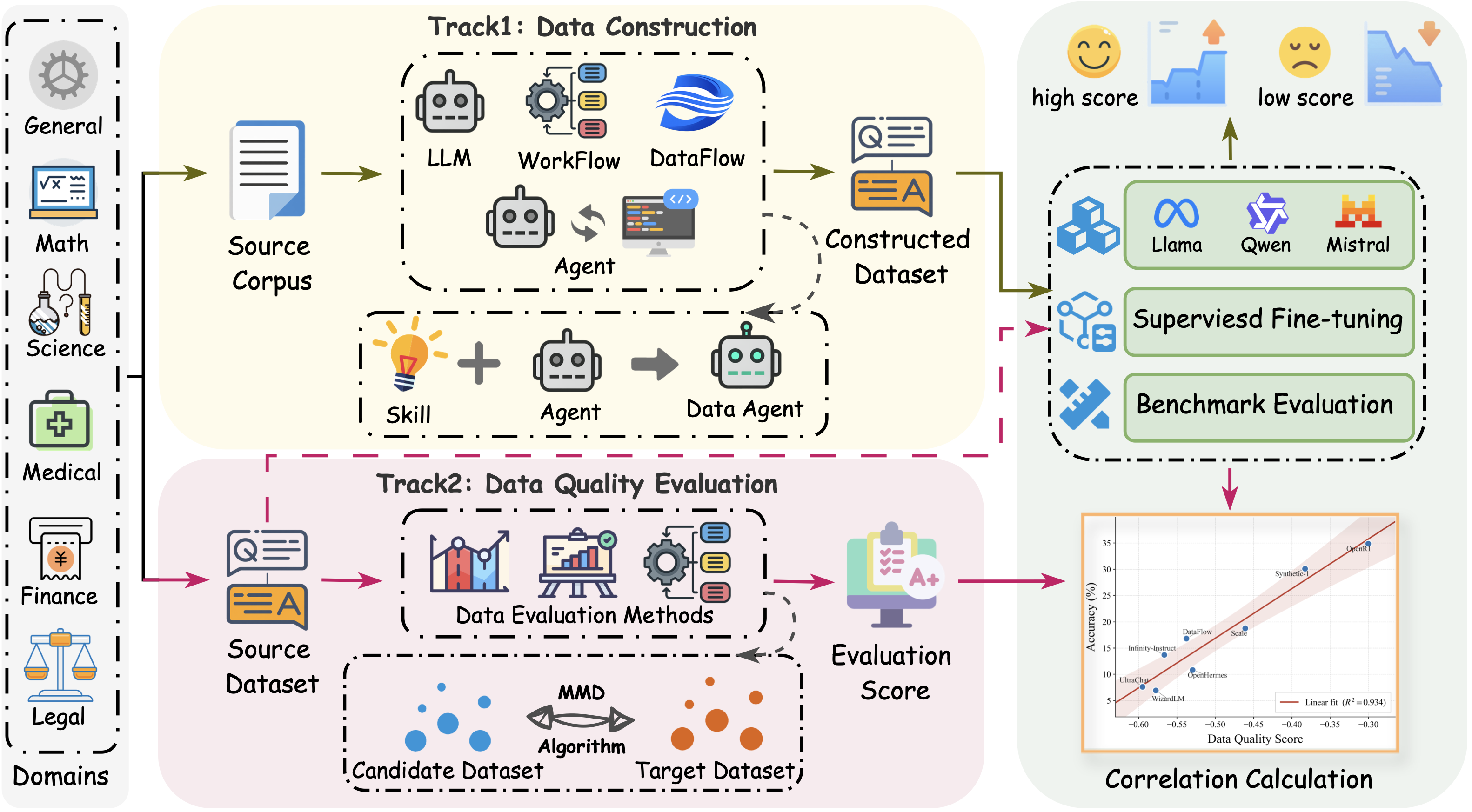
Track 1
Data Construction
Can a method turn raw domain materials into useful supervised fine-tuning data?
Input
Domain books, manuals, and long-form knowledge sources converted into a shared Markdown format.
Method Output
A supervised question-answer dataset synthesized from those raw sources.
Judgment
Fine-tune the same base model with the constructed data plus Dolly-15k, then evaluate on held-out domain benchmarks.
Released Baseline
Data-Construction-Skill, a skill-guided agent with reusable schemas, filtering rules, coverage checks, and validation utilities.